I’m happy to say that my advisor Ronen Eldan and I somewhat recently uploaded a paper to the arXiv under the title “Concentration on the Boolean hypercube via pathwise stochastic analysis” (https://arxiv.org/abs/1909.12067), wherein we prove inequalities on the Boolean hypercube using a cool continuous-time random process.
That’s quite a mouthful, I know, and quite unfortunately, Boolean analysis is not a standard part of any math curriculum that I know of, be it at the undergraduate, high school, or kindergarten level. In this post I explain a bit about what Boolean functions are and what sort of games you can play with them; a sort of catastrophic cubic crash course, if you will. The next post will talk about our actual result.
For your Boolean convenience, here is a small table of contents.
Boolean functions
A Boolean function is a function which takes as input a vector of 

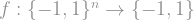
That’s it! Being so simple, Boolean functions can represent many things from many different disciplines, and it’s no wonder that they appear everywhere you look (though, as they say, what you see depends on what you are looking for, and this is especially true for mathematicians). To name a few examples:
- Social choice: A single bit
can represent the opinion of a voting-age citizen concerning some political matter, e.g whether or not Earth should break from the Intergalactic Federation (Earthxit). The vector
then represents the opinion of all
represents some way of deciding how to act based on those
if
and outputs
if
(i.e outputs
for some index
, corresponding to the idea that only the opinion of person

- Algorithms: A very large portion of theoretical computer science and algorithms deals with concrete questions of the form “given some data structure, how do I know if it satisfies some property?”. For example, given a graph on
vertices, does it contain a Hamiltonian path? Is it a tree? Does it contain a clique of size
? Is it 4 colorable? Is it isomorphic to some other graph? Is it planar? And many more. Now, a graph on
potential edges, and it is completely described by stating which of those edges appear, and which don’t. So a graph can be identified with a vector
corresponds to some possible edge:
if the edge is in the graph, and
if it is not. Thus, each “graph property” you can think of gives rise to a Boolean function.
For the connoisseur: Of course, the same is true not only for graphs; any Turing machine (which halts) gives a function on

Does this graph contain a clique of size 10? - Percolation: Similarly related to the idea of “graph properties” but totally deserving an entry of its own is the percolation function. In this example, you start with a square which is divided into hexagons. Each hexagon is colored either blue or yellow, and so can be described by a single bit
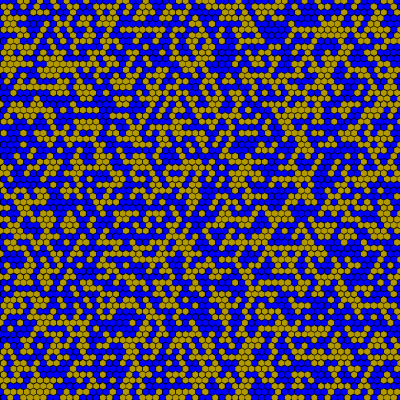
Is there a left-to-right crossing of yellow hexagons? - Combinatorics: A favorite pastime of mathematical combinators is to take an
, and ask all sorts of questions about how its different subsets interact with each other, such as “what is the largest possible family of subsets of
so that no set contains the other?“. As it turns out, a family
of subsets of
is in the subset and
then gives rise to a Boolean function
, with
if the subset represented by
is in
- And many more: There are a myriad other examples and uses. In fact, Boolean functions have already had a spotlight in this very blog, when I investigated random walks on the hypercube. Indeed, there are just too many to list. But that shouldn’t stop you from trying; as the saying goes, “The world is your oyster, and Boolean functions are the pearl”.
Inequalities
Mathematicians, being what they are, usually don’t care about any particular Boolean function and how to compute it, but rather are interested in general properties of Boolean functions, and how different properties relate to each other. And mathematicians, being what they are, have devised a fairly long list of properties and inequalities between them.One of the central quantities of a Boolean function is its influence, which is a measure of how important each individual bit
Definition: Pick 


![\mathrm{Inf}_i (f) = \mathbb{P}\left[f(x_1,x_2,\ldots,x_i,\ldots,x_n) \neq f(x_1,x_2,\ldots,-x_i,\ldots,x_n)\right].](https://s0.wp.com/latex.php?latex=%5Cmathrm%7BInf%7D_i+%28f%29+%3D+%5Cmathbb%7BP%7D%5Cleft%5Bf%28x_1%2Cx_2%2C%5Cldots%2Cx_i%2C%5Cldots%2Cx_n%29+%5Cneq+f%28x_1%2Cx_2%2C%5Cldots%2C-x_i%2C%5Cldots%2Cx_n%29%5Cright%5D.+&bg=ffffff&fg=888888&s=1&c=20201002)
The dictator function 
The definition of influence uses elementary probability, and this is very common in the analysis of Boolean functions. For example, when faced with a new Boolean function, one of the very first questions you will ask is “is it balanced?”, meaning, does it output
 if outputs as often as it outputs , but nonzero otherwise. Since there are possible values of to go through, the sum can potentially be as large as , and to be able to compare functions for different values, we usually use a normalized bias, whose range is in
if outputs as often as it outputs , but nonzero otherwise. Since there are possible values of to go through, the sum can potentially be as large as , and to be able to compare functions for different values, we usually use a normalized bias, whose range is in ![\left[-1,1\right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B-1%2C1%5Cright%5D+&bg=ffffff&fg=888888&s=1&c=20201002) :
:
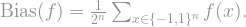
 is exactly the probability of picking any particular vector uniformly at random. The normalized bias can then be written as an expectation:
is exactly the probability of picking any particular vector uniformly at random. The normalized bias can then be written as an expectation:

 and be done with it. The probabilistic notation conveniently leads to the “variance” of a function, which is defined exactly like in probability:
and be done with it. The probabilistic notation conveniently leads to the “variance” of a function, which is defined exactly like in probability:

 , a function which is balanced (i.e has
, a function which is balanced (i.e has  ) will always have variance . However, the more biased a function is towards either or , the smaller its variance.
) will always have variance . However, the more biased a function is towards either or , the smaller its variance.
Having defined two different quantities, the first thing that a mathematician does is try to compare them. Here is a theorem, called the “Poincaré inequality”, which is true for all Boolean functions:
Theorem:

 . This means that the term on the right hand side is of size about
. This means that the term on the right hand side is of size about  , while the term on the left hand side is a mere puny ! That’s a lot of slack.
, while the term on the left hand side is a mere puny ! That’s a lot of slack.
A much more powerful (indeed, revolutionary) inequality is the one proven by Kahn, Kalai and Linial in 1988.
Theorem (KKL): Let 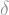


Here 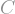
We are usually interested in the behavior of these types of theorems when the number of bits 


Fourier for all
The KKL inequality is the industry-standard, go-to inequality for Boolean functions; efficient, dependable, and quite importantly, analysable. Its most common proof showcases the mathematical gizmos and gadgets used in Boolean analysis. Let’s take a peek at them.At the core of everything Boolean lies the Fourier decomposition: Every function 
![f(x) = \sum_{S\subseteq [n]} \widehat{f}(S) \prod_{i\in S} x_i,](https://s0.wp.com/latex.php?latex=f%28x%29+%3D+%5Csum_%7BS%5Csubseteq+%5Bn%5D%7D+%5Cwidehat%7Bf%7D%28S%29+%5Cprod_%7Bi%5Cin+S%7D+x_i%2C+&bg=ffffff&fg=888888&s=1&c=20201002)
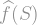 is called the “Fourier coefficient” of the set . Here are two ways to see why this is true:
is called the “Fourier coefficient” of the set . Here are two ways to see why this is true:
- The brute force way: One way to “compute” the function
, and ask, “is
!” Mathematically, this amounts to writing
whereis the function which returns
and
is
(i.e they have the same sign) and
(i.e they have different signs). Since we need every bit
, we just have
Plugging this into the sum over indicators and summing over possible monomials instead of over possible - The elegant way: Like everything elegant in the world, this way uses linear algebra. For a set
, denote
; this is called the “character” of
, the correlation between
and
vanishes:
Thus the set of charactersconstitute a complete orthonormal basis under the scalar product
, and so every function
) can be written as a linear combination of characters

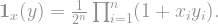
![\mathbb{E}[\chi_S \chi_T] = 0.](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B%5Cchi_S+%5Cchi_T%5D+%3D+0.+&bg=ffffff&fg=888888&s=1&c=20201002)
![\widehat{f}(S) = \langle f, \chi_S \rangle = \mathbb{E}[f \chi_S].](https://s0.wp.com/latex.php?latex=%5Cwidehat%7Bf%7D%28S%29+%3D+%5Clangle+f%2C+%5Cchi_S+%5Crangle+%3D+%5Cmathbb%7BE%7D%5Bf+%5Cchi_S%5D.+&bg=ffffff&fg=888888&s=1&c=20201002)
The second, elegant way has a few advantages. First, if you took a functional analysis course in kindergarten, it makes you feel proud to finally see it applied in a nontrivial discrete system. Congratulations! Second (and perhaps arguably more important), the connection to classical functional analysis automatically gives us access to a vast repertoire of theorems and results about this decomposition. For example, we immediately know that the decomposition is unique, or that an equality known as “Parseval’s identity” holds:
![\sum_{S \subseteq [n]} \widehat{f}(S)^2 = \langle f, f \rangle.](https://s0.wp.com/latex.php?latex=%5Csum_%7BS+%5Csubseteq+%5Bn%5D%7D+%5Cwidehat%7Bf%7D%28S%29%5E2+%3D+%5Clangle+f%2C+f+%5Crangle.+&bg=ffffff&fg=888888&s=1&c=20201002)
![\langle f,g \rangle = \mathbb{E}[fg]](https://s0.wp.com/latex.php?latex=%5Clangle+f%2Cg+%5Crangle+%3D+%5Cmathbb%7BE%7D%5Bfg%5D+&bg=ffffff&fg=888888&s=1&c=20201002) , this actually gives
, this actually gives
![\sum_{S \subseteq [n]} \widehat{f}(S)^2 = \mathbb{E}[f^2].](https://s0.wp.com/latex.php?latex=%5Csum_%7BS+%5Csubseteq+%5Bn%5D%7D+%5Cwidehat%7Bf%7D%28S%29%5E2+%3D+%5Cmathbb%7BE%7D%5Bf%5E2%5D.+&bg=ffffff&fg=888888&s=1&c=20201002) in terms of its Fourier coefficients: The expectation is just the coefficient of the empty set:
in terms of its Fourier coefficients: The expectation is just the coefficient of the empty set:
![\mathbb{E}[f] = \langle f, 1 \rangle = \langle f, \chi_{\emptyset} \rangle = \widehat{f}(\emptyset),](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Bf%5D+%3D+%5Clangle+f%2C+1+%5Crangle+%3D+%5Clangle+f%2C+%5Cchi_%7B%5Cemptyset%7D+%5Crangle+%3D+%5Cwidehat%7Bf%7D%28%5Cemptyset%29%2C+&bg=ffffff&fg=888888&s=1&c=20201002)
![\mathrm{Var}(f) = \mathbb{E}(f - \mathbb{E}[f])^2 = \sum_{S \neq \emptyset} \widehat{f}(S)^2](https://s0.wp.com/latex.php?latex=%5Cmathrm%7BVar%7D%28f%29+%3D+%5Cmathbb%7BE%7D%28f+-+%5Cmathbb%7BE%7D%5Bf%5D%29%5E2+%3D+%5Csum_%7BS+%5Cneq+%5Cemptyset%7D+%5Cwidehat%7Bf%7D%28S%29%5E2+&bg=ffffff&fg=888888&s=1&c=20201002)
This is very neat; we have found a way to express the variance of a function using its Fourier coefficients. Perhaps, if the same thing can be done for the influences
Definition: The 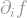
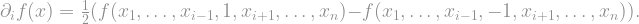
The derivative function can take on three possible values: 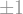

![\mathrm{Inf}_i(f) = \mathbb{E}[\partial_i f(x)^2].](https://s0.wp.com/latex.php?latex=%5Cmathrm%7BInf%7D_i%28f%29+%3D+%5Cmathbb%7BE%7D%5B%5Cpartial_i+f%28x%29%5E2%5D.++&bg=ffffff&fg=888888&s=1&c=20201002) , then we also know the Fourier representation of its derivative: You can differentiate each monomial separately, and find that
, then we also know the Fourier representation of its derivative: You can differentiate each monomial separately, and find that

![\mathbb{E}[\partial_i f(x)^2] = \sum_{S \text{ s.t } i\in S} \widehat{f}(S)^2 .](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B%5Cpartial_i+f%28x%29%5E2%5D+%3D+%5Csum_%7BS+%5Ctext%7B+s.t+%7D+i%5Cin+S%7D+%5Cwidehat%7Bf%7D%28S%29%5E2+.+&bg=ffffff&fg=888888&s=1&c=20201002) , we’ll again get a sum involving the Fourier coefficients of , but now each coefficient will be multiplied by some factor: Each set appears once for each
, we’ll again get a sum involving the Fourier coefficients of , but now each coefficient will be multiplied by some factor: Each set appears once for each  , so each Fourier coefficient is counted
, so each Fourier coefficient is counted 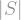 times. The empty set
times. The empty set  won’t be counted at all, of course. Thus
won’t be counted at all, of course. Thus
![\sum_i \mathrm{Inf}_i(f) = \sum_i \mathbb{E}[\partial_i f(x)^2] = \sum_{S \neq \emptyset} |S| \widehat{f}(S)^2.](https://s0.wp.com/latex.php?latex=%5Csum_i+%5Cmathrm%7BInf%7D_i%28f%29+%3D+%5Csum_i+%5Cmathbb%7BE%7D%5B%5Cpartial_i+f%28x%29%5E2%5D+%3D+%5Csum_%7BS+%5Cneq+%5Cemptyset%7D+%7CS%7C+%5Cwidehat%7Bf%7D%28S%29%5E2.+&bg=ffffff&fg=888888&s=1&c=20201002) had exactly the same form, but without the term multiplying each Fourier coefficient. But
had exactly the same form, but without the term multiplying each Fourier coefficient. But 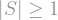 always, so the sum of influences is always larger than the variance. And, if your body is willing and your spirit is strong, you can even deduce from these representations for which functions the Poincaré inequality is actually an equality.
always, so the sum of influences is always larger than the variance. And, if your body is willing and your spirit is strong, you can even deduce from these representations for which functions the Poincaré inequality is actually an equality.
Hypercontractivity
Unfortunately, the KKL inequality requires more than basic manipulation of Fourier coefficients (indeed, it requires advanced manipulation of Fourier coefficients). The standard proof uses what is known as the “hypercontractive inequality”. Summed up in one cryptic sentence, this inequality tells you how different ways of sizing up a function (aka different norms) relate to each other when you smooth out the sharp features of the function (aka adding noise). Let’s see what all of that means.One important way of studying the influences of a function is to see how it changes under noise. You can write entire books on this topic (indeed, people have), so I’ll just present the basics here.
First, what is noise? Suppose that 
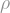

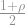
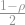

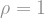

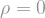
Using this definition of noise, we can look at a “smoothed out” version of
Definition: The noise operator of 
![T_\rho f (x) = \mathbb{E}[f(y)],](https://s0.wp.com/latex.php?latex=T_%5Crho+f+%28x%29+%3D+%5Cmathbb%7BE%7D%5Bf%28y%29%5D%2C+&bg=ffffff&fg=888888&s=1&c=20201002) is -correlated with .
is -correlated with .
I say that this is “smoothed” out because what it does in effect is take weighted averages over all the values of 
![T_0f = \mathbb{E}[f]](https://s0.wp.com/latex.php?latex=T_0f+%3D+%5Cmathbb%7BE%7D%5Bf%5D+&bg=ffffff&fg=888888&s=1&c=20201002)
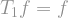
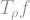
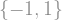
![[-1,1]](https://s0.wp.com/latex.php?latex=%5B-1%2C1%5D+&bg=ffffff&fg=888888&s=1&c=20201002)
For the connoisseur: If you peek inside textbooks, you might see 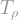

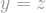
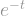
It can sometimes be a bit hard to understand how ![\mathbb{E}[\alpha f+\beta g] = \alpha \mathbb{E}[f] + \beta \mathbb{E}[g]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B%5Calpha+f%2B%5Cbeta+g%5D+%3D+%5Calpha+%5Cmathbb%7BE%7D%5Bf%5D+%2B+%5Cbeta+%5Cmathbb%7BE%7D%5Bg%5D+&bg=ffffff&fg=888888&s=1&c=20201002)
![T_\rho f(x) = \sum_{S \subseteq [n]} \widehat{f}(S) \cdot \left( T_\rho \prod_{\i\in S} x_i \right)(x).](https://s0.wp.com/latex.php?latex=T_%5Crho+f%28x%29+%3D+%5Csum_%7BS+%5Csubseteq+%5Bn%5D%7D+%5Cwidehat%7Bf%7D%28S%29+%5Ccdot+%5Cleft%28+T_%5Crho++%5Cprod_%7B%5Ci%5Cin+S%7D+x_i+%5Cright%29%28x%29.++&bg=ffffff&fg=888888&s=1&c=20201002) on the monomial
on the monomial  is relatively easy to understand: Since all the bits are independent, it’s just the product of on each individual , and each one of those is equal to
is relatively easy to understand: Since all the bits are independent, it’s just the product of on each individual , and each one of those is equal to
![\left(T_\rho x_i\right)(x) = \mathbb{E}[y_i] = \left(\frac{1+\rho}{2}\right)x_i + \left(\frac{1-\rho}{2}\right)(-x_i)](https://s0.wp.com/latex.php?latex=%5Cleft%28T_%5Crho+x_i%5Cright%29%28x%29+%3D+%5Cmathbb%7BE%7D%5By_i%5D+%3D+%5Cleft%28%5Cfrac%7B1%2B%5Crho%7D%7B2%7D%5Cright%29x_i+%2B++%5Cleft%28%5Cfrac%7B1-%5Crho%7D%7B2%7D%5Cright%29%28-x_i%29++&bg=ffffff&fg=888888&s=1&c=20201002)

![T_\rho f(x) = \sum_{S \subseteq [n]} \widehat{f}(S) \cdot \rho^{|S|} \prod_{\i\in S} x_i,](https://s0.wp.com/latex.php?latex=T_%5Crho+f%28x%29+%3D+%5Csum_%7BS+%5Csubseteq+%5Bn%5D%7D+%5Cwidehat%7Bf%7D%28S%29+%5Ccdot+%5Crho%5E%7B%7CS%7C%7D+%5Cprod_%7B%5Ci%5Cin+S%7D+x_i%2C++&bg=ffffff&fg=888888&s=1&c=20201002) , then we know the Fourier coefficients of ! Namely,
, then we know the Fourier coefficients of ! Namely,
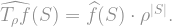
While the noise operator certainly changes the values of 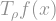
![\mathbb{E}[f ^2] \geq \mathbb{E}[(T_\rho f)^2]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Bf+%5E2%5D+%5Cgeq+%5Cmathbb%7BE%7D%5B%28T_%5Crho+f%29%5E2%5D+&bg=ffffff&fg=888888&s=1&c=20201002)
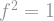 always and
always and  can be smaller than ). Many doors now open, and the mathematically-curious can wonder how expectations of quantities of relate to expectations of quantities of
can be smaller than ). Many doors now open, and the mathematically-curious can wonder how expectations of quantities of relate to expectations of quantities of  . One class of heavily-investigated such quantity is the
. One class of heavily-investigated such quantity is the  -norm:
-norm:
Definition: Let 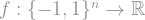


![\|f\|_p = \left(\mathbb{E}[|f|^p]\right)^{1/p}.](https://s0.wp.com/latex.php?latex=%5C%7Cf%5C%7C_p+%3D+%5Cleft%28%5Cmathbb%7BE%7D%5B%7Cf%7C%5Ep%5D%5Cright%29%5E%7B1%2Fp%7D.+&bg=ffffff&fg=888888&s=1&c=20201002)
The 
![\|f\|_2 = \left(\mathbb{E}[f^2]\right)^{1/2} = \left(\sum_{S \subseteq [n]} \widehat{f}(S)^2 \right)^{1/2};](https://s0.wp.com/latex.php?latex=%5C%7Cf%5C%7C_2+%3D+%5Cleft%28%5Cmathbb%7BE%7D%5Bf%5E2%5D%5Cright%29%5E%7B1%2F2%7D+%3D+%5Cleft%28%5Csum_%7BS+%5Csubseteq+%5Bn%5D%7D+%5Cwidehat%7Bf%7D%28S%29%5E2+%5Cright%29%5E%7B1%2F2%7D%3B+&bg=ffffff&fg=888888&s=1&c=20201002) -norm, other -norms are uniformly studied (if not loved). A bit of analysis using convexity can show the following inequality between norms: If
-norm, other -norms are uniformly studied (if not loved). A bit of analysis using convexity can show the following inequality between norms: If 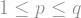 , then
, then
 only increases the size of the norm. To get a feel of why this is true, think of a function which outputs on a single input
only increases the size of the norm. To get a feel of why this is true, think of a function which outputs on a single input 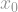 , and outputs on all the rest. The expectation
, and outputs on all the rest. The expectation ![\mathbb{E}[|f|^p]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B%7Cf%7C%5Ep%5D+&bg=ffffff&fg=888888&s=1&c=20201002) will always be , but the root
will always be , but the root  on the outside makes the norm larger for larger values of .
on the outside makes the norm larger for larger values of .
For the connoisseur: The keen-eyed among you will have noticed that the inequality between norms is exactly the opposite of norms for functions on 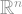
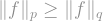

The inequality 


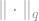


With this notion in mind, we come to perhaps the most famous theorem in the study of norms of Boolean functions, the “Hypercontractive inequality”. This is a really fancy-sounding, sex-appealing name for a theorem which relates the norm of
Theorem: For all 

Since 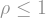



When I just started learning about Boolean functions, I didn’t know what all the fuss was about. After all, it’s just another inequality. But if there’s one thing that the analysts are good at, it is squeezing seemingly obscure inequalities to their very last drop of sweet, theorem-proving juice. Let’s see how that works out for the KKL inequality.
Proving KKL
Armed with the hypercontractive inequality, proving KKL is as easy as a brisk walk in an-dimensional park; the elegant proof I present here is from the book on noise sensitivity.
In essence, the proof uses the Fourier decomposition of to show that much of the contribution to the variance can be bounded by smoothed-out versions of the derivatives of . These smoothed-out versions can then be bounded using the hypercontractivity theorem. To save you some scrolling, here is the KKL inequality:
Theorem (KKL): Let
Assume for now that 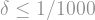
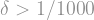
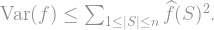 ; since
; since 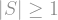 , this only made the summands larger. When we did this, the right hand side was equal to the sum of influences, by the Fourier analysis we did before.
, this only made the summands larger. When we did this, the right hand side was equal to the sum of influences, by the Fourier analysis we did before.
This time, we’ll do something similar, but use a trick before multiplying by 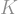
 as usual. But for the second sum, since
as usual. But for the second sum, since 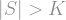 there, we actually multiply by
there, we actually multiply by  ; this is still a number larger than , so we still only increase the size of the summands:
; this is still a number larger than , so we still only increase the size of the summands:


 and divide by
and divide by 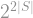 ; this only makes each summand larger, since
; this only makes each summand larger, since 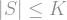 . We can also extend the sum to all , since that only adds more terms, and we arrive at the inequality
. We can also extend the sum to all , since that only adds more terms, and we arrive at the inequality
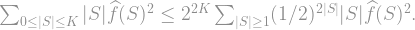 does to the Fourier representation of a function: It adds a factor of
does to the Fourier representation of a function: It adds a factor of 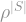 to each Fourier coefficient. So if we look, for example, at the effect of on the derivative of in direction , we get
to each Fourier coefficient. So if we look, for example, at the effect of on the derivative of in direction , we get
 -norm of this expression is, by Parseval’s identity, just the sum of square of coefficients:
-norm of this expression is, by Parseval’s identity, just the sum of square of coefficients:
 ; if we do that, we’ll count each set as many times as there are indices in it (very similar to the calculation for the sum of influences), giving
; if we do that, we’ll count each set as many times as there are indices in it (very similar to the calculation for the sum of influences), giving
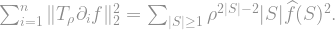
 , and we have a bound for our initial sum:
, and we have a bound for our initial sum:
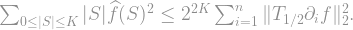 -norm of the smoothed
-norm of the smoothed 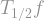 is smaller than the
is smaller than the  -norm of the original function , so
-norm of the original function , so
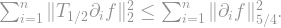
 -norm of the derivative to the power of is just the influence of the function , since the derivative is when there is a change in the function’s value and otherwise! And since every influence is bounded by by definition, we reach the final bound on the first sum:
-norm of the derivative to the power of is just the influence of the function , since the derivative is when there is a change in the function’s value and otherwise! And since every influence is bounded by by definition, we reach the final bound on the first sum:

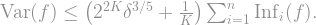 which will minimize the expression in the parenthesis. Notice that as increases, the term
which will minimize the expression in the parenthesis. Notice that as increases, the term  increases, but the term
increases, but the term  decreases. Typically, these types of expressions are minimized when both terms are equal, or at least, nearly equal. To do this, choose
decreases. Typically, these types of expressions are minimized when both terms are equal, or at least, nearly equal. To do this, choose
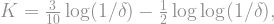 -power vanishes, and we are left with . As for the second term, since we assumed way way up in the beginning of this section that
-power vanishes, and we are left with . As for the second term, since we assumed way way up in the beginning of this section that  , the
, the 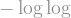 factor doesn't really make much of a dent in the much larger
factor doesn't really make much of a dent in the much larger  term, and
term, and 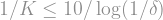 . So all in all,
. So all in all,
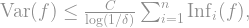
(And what if 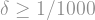

All in all, I think this is a nice proof. The choice 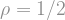

Very nice blog post, enjoyed reading it! There may be a mistake in the formula after the paragraph that starts with “Recall what the heat operator…”. The rhs of this equation seems to be for \partial_i T_{\rho} f, not T_{\rho}\partial_i f — otherwise I think \rho has to be taken to the power |S|-1, not |S|.
Seems you are right. Fixed, thanks!