I’m happy to say that I recently uploaded a paper to the arXiv under the title “A conformal Skorokhod embedding” (https://arxiv.org/abs/1905.00852). In this post, I’d like to explain what the Skorokhod embedding problem is, how I came across it, some previously known solutions, and my own tiny contribution. But really, all of this is just a sorry excuse to post some pretty images which come up along the way. I’ll try to write a fairly self-contained exposition, leaving the sketch of the technical details to the very end.

Brownian motion and the Skorokhod embedding
Our main player in all of this is Brownian motion. Named after Robert Brown, it is the probabilistic community’s industry-approved gold-standard for diffusions, Markov chains, and random walks. Basically, a Brownian motion path 


If the particle is travelling in one dimension, its path as a function of time might look like this:

In two dimensions, the path might look like this (now it is more difficult to draw the time axis, so different times are represented by color, with blue at the beginning and purple at the end):

One mathematical way of describing Brownian motion is as follows. Suppose that a particle starts at position 





10 steps 
100 steps 
1000000 steps
This random-walk description can also be done in two or three or any number of dimensions. A very nice property of mutli-dimensional Brownian motion is that it is just composed of a bunch of individual, independent one-dimensional Brownian motions – one for each direction.
Mathematicians take quite a fancy to Brownian motion, and for many reasons: Because it is simple (so far as stochastic processes go), because it appears almost everywhere, and because it is the natural scaling limit of random walks, to name a few. But mostly, they like it because they can prove things about it, and the mathematical literature is filled with questions (and sometimes, even answers) about how many times Brownian motions hit a point, or how two such motions intersect each other, or how to integrate, solve differential equations, and make coffee using Brownian motion.
Skorokhod, being a mathematician, was no exception. He was interested in the following question. Suppose you wanted to flip a coin, that is, randomly get either Heads (which we denote by the number “1”) or Tails (which we denote by the number “-1”). You reach into your pocket searching for a coin, but are both amazed and abashed to discover that you only have a Brownian motion
The answer is: Yes! Here is Skorokhod’s way of doing it: Since Brownian motion is symmetric, meaning it has equal probability of being at either 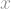



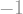

Doing something like the above is called stopping the Brownian motion, and the time at which we stop it is called a stopping time. Note that this is a random time, which actually depends on the randomness imbued in the Brownian motion: For one particular run it may be that 

Skorokhod was interested in a generalization: Suppose that instead of just flipping a coin, you wanted to simulate some other, general, probability distribution. Can you simulate a continuous distribution, such as a Gaussian distribution? How about a discrete one, like a geometric distribution? Or what about nasty, everywhere-non-differentiable yet non-atomic distributions, demons from beyond the depth of Hell for which humankind has no name? (I’m looking at you, Mr. Every-Rational-Number-Has-Positive-Weight-Distribution)

The answer is: Yes! (with one small caveat on the variance) And you can do it by using stopping times, too:
Theorem: Let 


This theorem is often called Skorokhod’s embedding theorem (which to me always sounded like a Dungeons and Dragons spell), probably because it embeds some other distribution inside Brownian motion.
Over the years there have been many proofs and generalizations of this theorem. Below are my two favorites (which you can (but shouldn’t) skip if you accidentally just want to see my solution (gosh, I’m blushing!))
Two cool solutions
First cool solution
The first cool solution is by Dubins. We already know when to stop Brownian motion when we want to get the 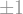



Dubins says this: First, run the Brownian motion until 


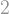


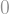


Actually, since 



This argument generalizes quite naturally to almost any probability distribution. Here I’ll show a continuous example. The following image is the density function of some distribution (a continuous histogram of the distribution, if you will):

The distribution can be divided into two parts: The positive numbers, and the negatives. We can compute the normalized mean of each part, that is, compute ![\mathbb{E}[X | X > 0]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BX+%7C+X+%3E+0%5D+&bg=ffffff&fg=888888&s=1&c=20201002)
![\mathbb{E}[X | X < 0]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BX+%7C+X+%3C+0%5D+&bg=ffffff&fg=888888&s=1&c=20201002)

So as a first step, run the Brownian motion until it hits one of the pink lines. For the sake of this example, let’s suppose that you hit the positive side.

Having done that, we now restrict ourselves, and say: Wherever else the Brownian motion will go, we will never return to the negative number range. The negative numbers are dead to us! (because we will make sure to always stop before we reach them). The remaining probability mass can be normalized, giving us a new distribution:

We can repeat this process again. If we hit the left barrier this time,

then we are left with the following:

Repeat at leisure. You can leave it to Dubins to prove that this process converges, and the final stopping time will be equal to infinitely many, shorter and shorter stopping times,

You can read Dubins’ original paper here.
Second cool solution
The second cool solution is by Root. Root also generalizes the 


The stopping time is then just first time that the Brownian motion
And he was right! I won’t go into the details, but the gist of Root’s argument is this. First he showed that such barriers exist for every atomic distribution, that is, every distribution which is supported on a finite number of numbers:

Once he had his finite collection of lines, Root proved that when taking a limit of finite atomic distributions which converge to a general distribution, the barrier converges as well.

You can read Root’s original paper here.
How I stumbled upon the problem
To be frank, a couple of months ago I was just an ordinary bloke, completely unaware that Skorokhod even had a problem with embeddings, not to mention that he solved it. I was working at the time on generalizing an approach used by my advisor, Ronen Eldan.
You see, Eldan, being a mathematician, also loves Brownian motion, and so much so that he uses it to manufacture practically all his other distributions, often with great success. One distribution which repeatedly comes up is the “uniform distribution on the Boolean hypercube”. This is a fancy name for the distribution on vectors of the form 


So, naturally, Eldan generates the 
It all relies on a fact we stated at the beginning, that 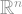
Here’s a representation of this process in three dimensions (so we are going to generate a random vector with three components of either

After the Brownian motion hits the rightmost face, it is confined to it and continues its journey on it:

Finally, after hitting one the bottom edge, we are left with a one-dimensional Brownian motion, with which we are quite familiar:

Note that unlike before, the Brownian motion doesn’t have to start at 0 at each successive stage. For example, in this particular case, the Brownian motion hit the face of the cube at the point 

Here is the entire trajectory:

The reason that Eldan even deals with all of this high-dimensional geometry stuff, and doesn’t just take the naive perspective of “![[-1,1]](https://s0.wp.com/latex.php?latex=%5B-1%2C1%5D+&bg=ffffff&fg=888888&s=1&c=20201002)
My solution
Like Root’s solution, my approach also involves looking at some geometric barrier which the Brownian motion is supposed to hit. But while Root barrier inspects when the graph 


There are two main ingredients in my construction. The first is a practical result from probability and statistics, called the “inverse sampling method”, which can be seen as a baby, non-time-dependent version of the Skorokhod embedding problem. Suppose once more that you want to flip a coin (getting the value 
![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D+&bg=ffffff&fg=888888&s=1&c=20201002)


As (almost) always in mathematics, this method can be applied to general distributions 

![F_\mu(x) = \mathbb{P}[x \leq X].](https://s0.wp.com/latex.php?latex=F_%5Cmu%28x%29+%3D+%5Cmathbb%7BP%7D%5Bx+%5Cleq+X%5D.+&bg=ffffff&fg=888888&s=1&c=20201002)
For a coin flip, the cumulative distribution is quite simple: The probability of being strictly less than 

This is an increasing function, so we can take what is called its “generalized inverse”, 

If you stare long enough at the inverse of the cumulative distribution function of the coin flip, you might notice something peculiar: It attains the value 

The statement of the inverse sampling method is that this trick works for all distributions

The second ingredient in my construction is called conformal invariance, which is a fancy name for “if you rotate something that is rotation invariant, it stays the same”. I’ll explain (but won’t go too much into the details). The plane 




Planar Brownian motion is rotationally invariant – it is equally likely to go in any one direction as the other. So it really doesn’t care if you rotate it at all. And since Brownian motion is self-similar (in that, if you zoom in on it, it looks the same), multiplying the motion itself by a constant is the same as “speeding up or slowing down time”: If you blow up the motion so that points that were very close to the origin are now very far, it’s equivalent to boosting up the speed of the motion, so that in a small amount of time it can zip across the plane.
Summing things up, since conformal transformations locally only scale and rotate, they don’t really do anything to Brownian motion: The rotation is shrugged off, and at most, the scaling can make it go faster or slower at some point. That’s the content of the phrase “Brownian motion is conformally invariant”: If 



Alright! It’s time to combine the pieces. We start with the observation that if we run Brownian motion until it hits a circle of radius ![[0,2\pi]](https://s0.wp.com/latex.php?latex=%5B0%2C2%5Cpi%5D+&bg=ffffff&fg=888888&s=1&c=20201002)

The inverse sampling method says that if 




which is the distribution we want to get!
However, these are not the rules of the game. We can’t just apply any function we want to the point after we have stopped – the whole point of Skorokhod’s theorem is to find a time
Here steps in the conformal invariance. Instead of applying just the function 





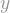


Now we are in good shape! Since 


That’s basically all there is to my plan of attack: Find a conformal

I won’t go deep into the details of how to obtain the desired conformal function
Instead of working with 


From the Fourier coefficients 

This construction takes advantage of the fact that the Fourier series and the power series agree on the unit circle. Indeed, for 



So if the angle 


